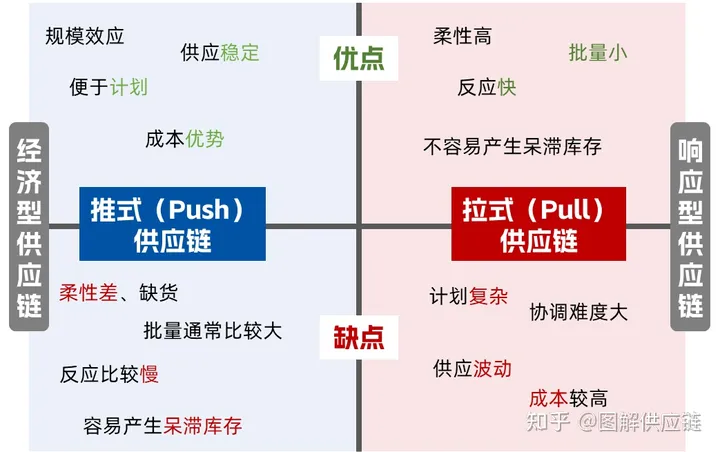
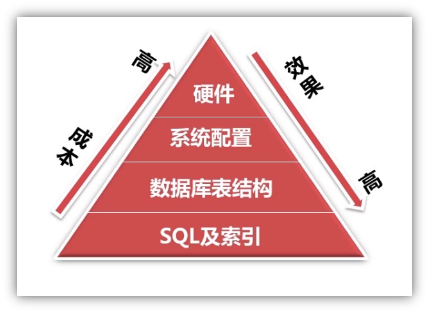
1、数据库优化方向
A、SQL及索引优化
根据需求写出良好的SQL,并创建有效的索引,实现某一种需求可以多种写法,这时候我们就要选择一种效率最高的写法。这个时候就要了解sql优化
B、数据库表结构优化
根据数据库的范式,设计表结构,表结构设计的好直接关系到写SQL语句。
C、系统配置优化
大多数运行在Linux机器上,如tcp连接数的限制、打开文件数的限制、安全性的限制,因此我们要对这些配置进行相应的优化。
D、硬件配置优化
选择适合数据库服务的cpu,更快的IO,更高的内存;cpu并不是越多越好,某些数据库版本有最大的限制,IO操作并不是减少阻塞。
注:通过上图可以看出,该金字塔中,优化的成本从下而上逐渐增高,而优化的效果会逐渐降低。
2、前置准备
2.1、MySQL 安装与卸载
Centos7 安装 MySQL5.7 步骤_centos7安装mysql5.7教程-CSDN博客文章浏览阅读4.4k次,点赞10次,收藏18次。Centos7 安装 MySQL5.7 步骤_centos7安装mysql5.7教程https://blog.csdn.net/weixin_54626591/article/details/133907510
2.2、数据库版本选择
2.3、准备数据
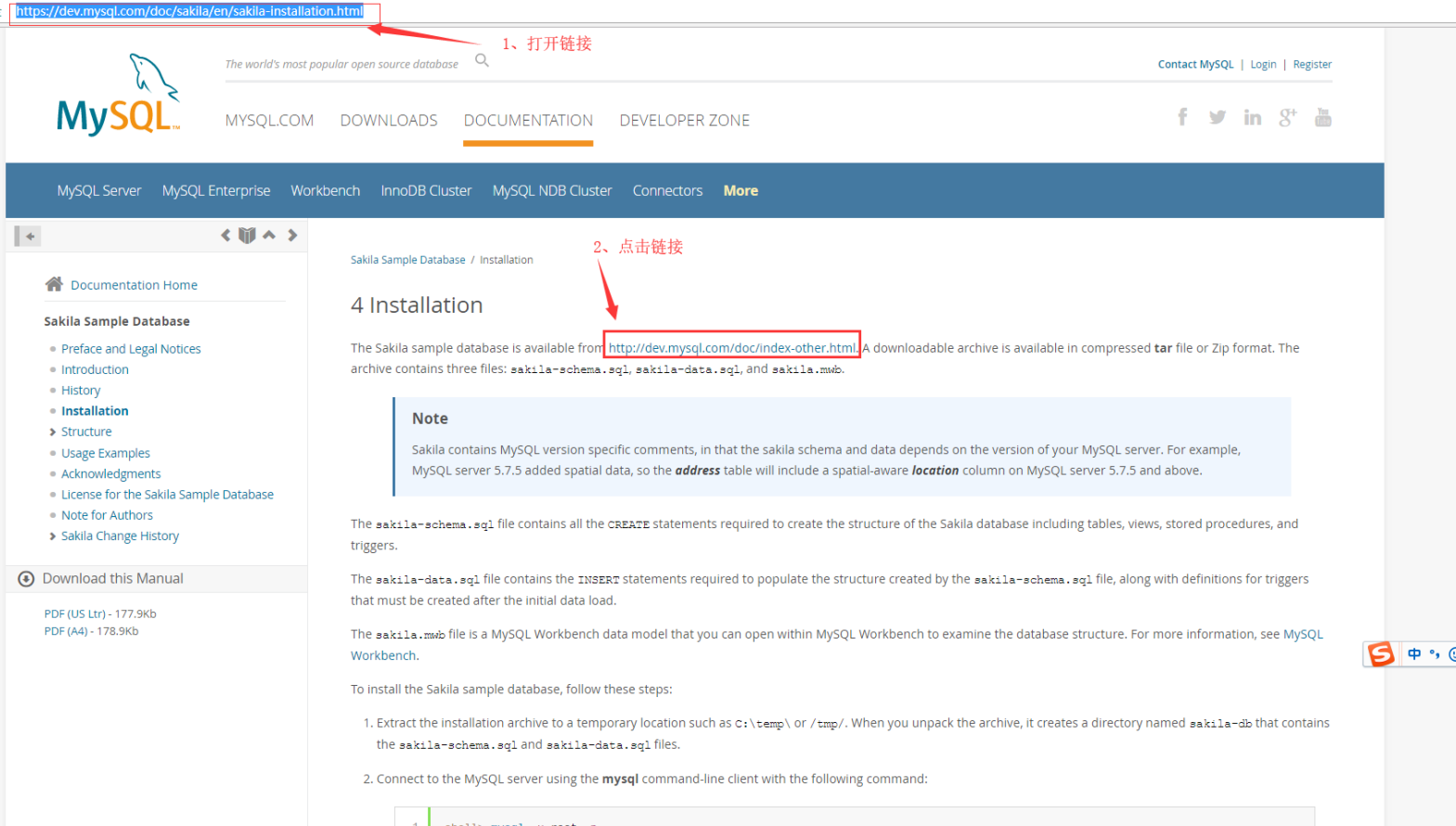
访问 下载地址,根据如下图操作步骤获取:

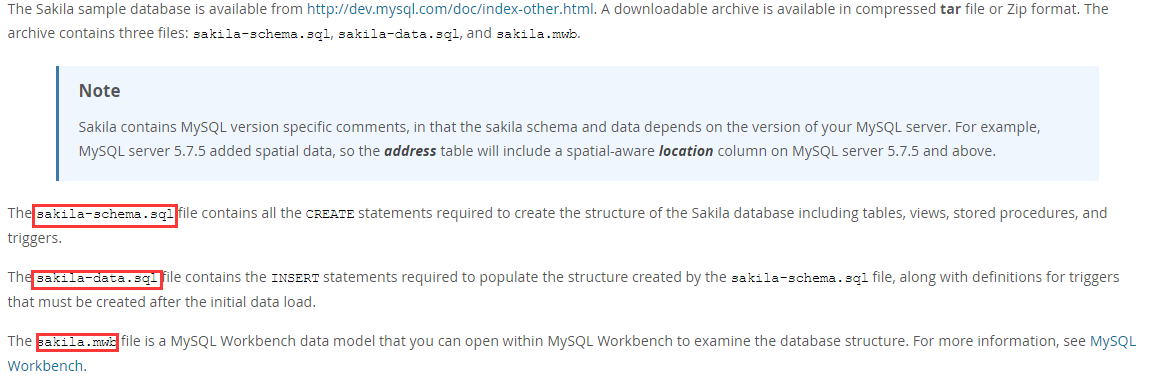
sakila-db.zip压缩包所包含的文件如下解释
数据加载步骤:
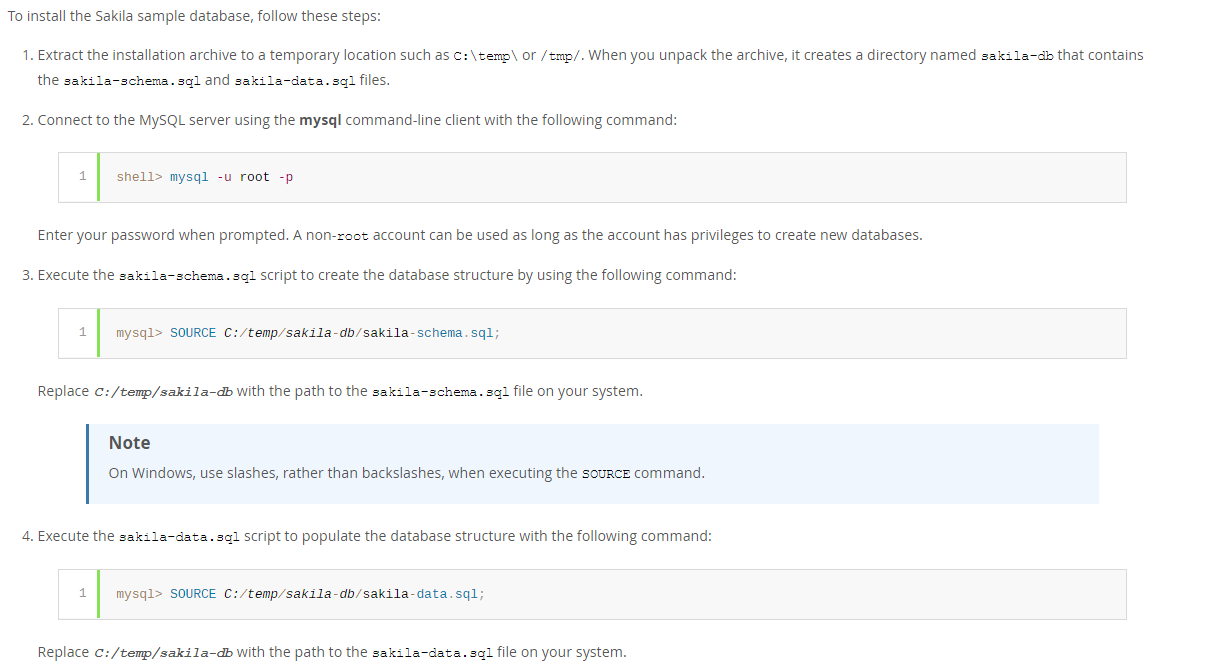
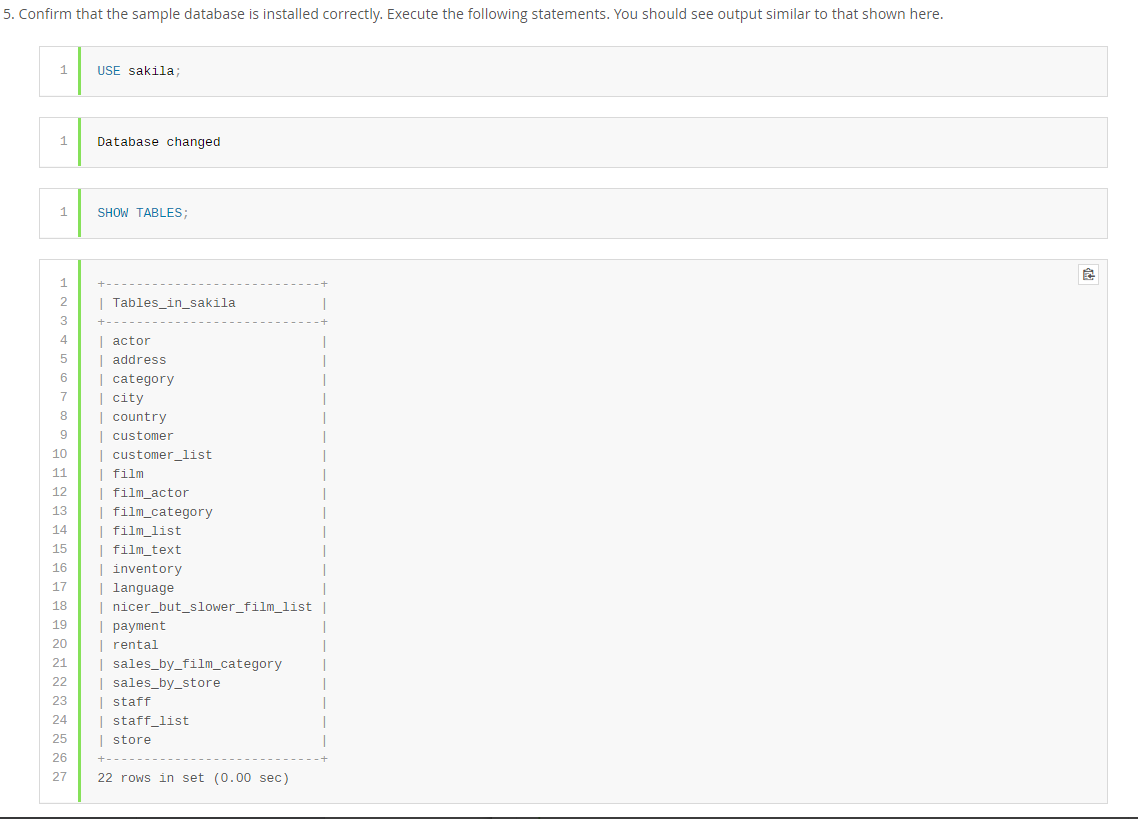
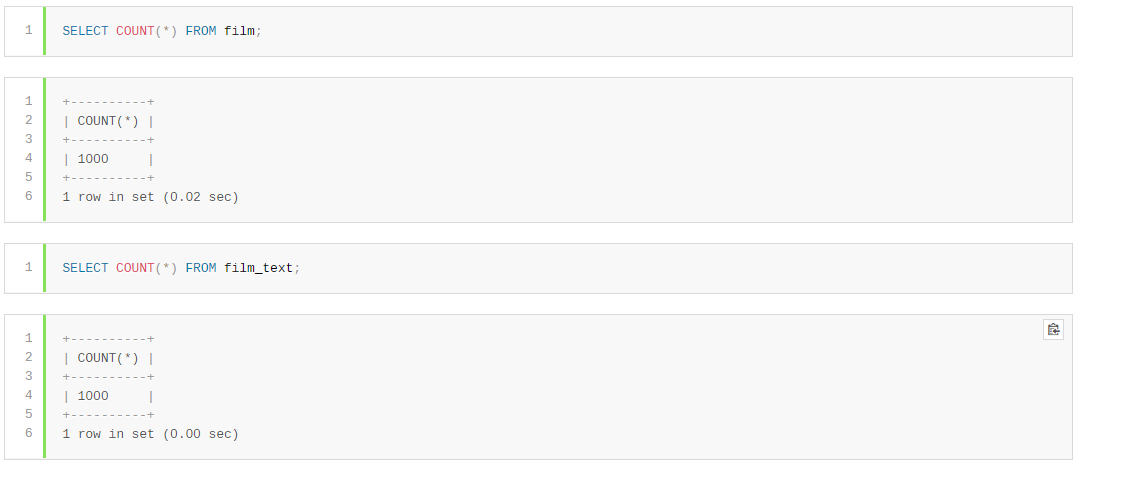
2.4、表结构关系
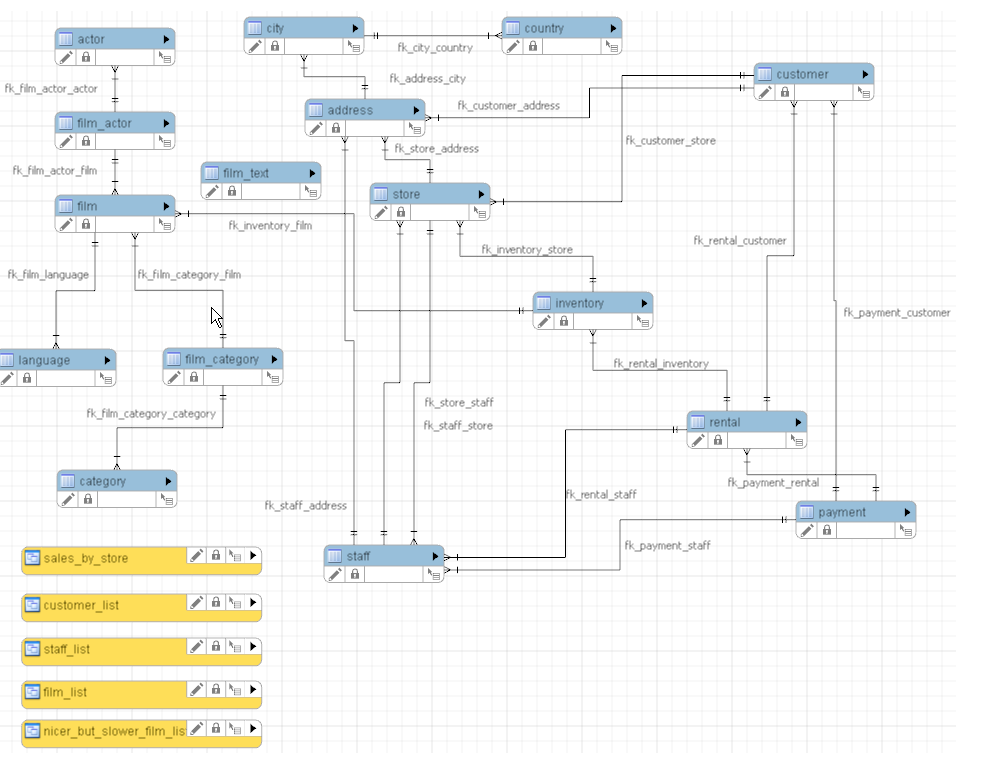
2.5、慢查询检查
2.5.1、检查慢查询日志是否开启
show variables like 'slow_query_log';
方式一:开启配置
-- 查看是否开启慢查询日志
show variables like 'slow_query_log';
-- 慢查询日志的位置
set global slow_query_log_file=' /usr/share/mysql/sql_log/mysql-slow.log'
-- 开启慢查询日志
set global log_queries_not_using_indexes=on;
-- 大于1秒钟的数据记录到慢日志中,如果设置为默认0,则会有大量的信息存储在磁盘中,磁盘很容易满掉
set global long_query_time=1; 方式二:修改配置文件
使用 yum 安装的或者 rpm 安装的可以在以下路径查找相关配置并修改(为修改的前提):
- MySQL二进制文件默认安装路径:
/usr/bin - MySQL配置文件默认安装路径:
/etc/my.cnf - MySQL数据文件默认安装路径:
/var/lib/mysql - MySQL日志文件默认安装路径:
/var/log/mysql - MySQL启动脚本默认安装路径:
/etc/init.d/mysql
2.5.2、查看所有日志的变量信息
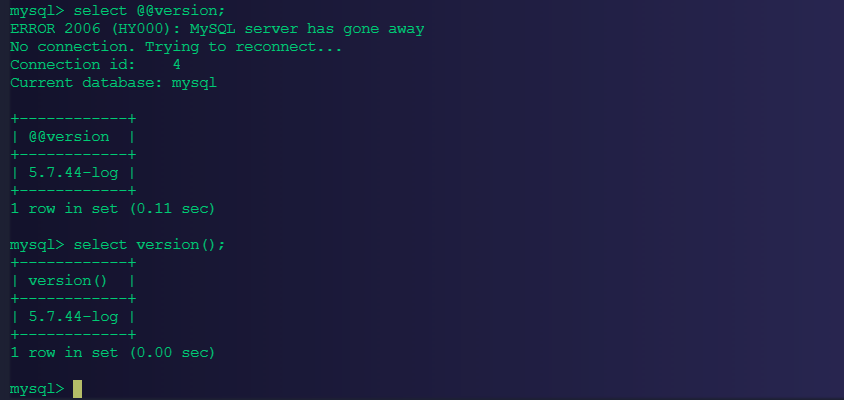
mysql> show variables like '%log%';
+--------------------------------------------+-----------------------------------------+
| Variable_name | Value |
+--------------------------------------------+-----------------------------------------+
| back_log | 80 |
| binlog_cache_size | 32768 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_error_action | ABORT_SERVER |
| binlog_format | ROW |
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
| binlog_gtid_simple_recovery | ON |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_row_image | FULL |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | COMMIT_ORDER |
| expire_logs_days | 0 |
| general_log | OFF |
| general_log_file | /var/lib/mysql/192.log |
| innodb_api_enable_binlog | OFF |
| innodb_flush_log_at_timeout | 1 |
| innodb_flush_log_at_trx_commit | 1 |
| innodb_locks_unsafe_for_binlog | OFF |
| innodb_log_buffer_size | 16777216 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_log_write_ahead_size | 8192 |
| innodb_max_undo_log_size | 1073741824 |
| innodb_online_alter_log_max_size | 134217728 |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| log_bin | OFF |
| log_bin_basename | |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| log_builtin_as_identified_by_password | OFF |
| log_error | /var/log/mysqld.log |
| log_error_verbosity | 3 |
| log_output | FILE |
| log_queries_not_using_indexes | ON |
| log_slave_updates | OFF |
| log_slow_admin_statements | OFF |
| log_slow_slave_statements | OFF |
| log_statements_unsafe_for_binlog | ON |
| log_syslog | OFF |
| log_syslog_facility | daemon |
| log_syslog_include_pid | ON |
| log_syslog_tag | |
| log_throttle_queries_not_using_indexes | 0 |
| log_timestamps | UTC |
| log_warnings | 2 |
| max_binlog_cache_size | 18446744073709547520 |
| max_binlog_size | 1073741824 |
| max_binlog_stmt_cache_size | 18446744073709547520 |
| max_relay_log_size | 0 |
| relay_log | |
| relay_log_basename | /var/lib/mysql/192-relay-bin |
| relay_log_index | /var/lib/mysql/192-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | FILE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| slow_query_log | ON |
| slow_query_log_file | /usr/share/mysql/sql_log/mysql-slow.log |
| sql_log_bin | ON |
| sql_log_off | OFF |
| sync_binlog | 1 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+--------------------------------------------+-----------------------------------------+
74 rows in set (0.03 sec)
mysql>在MySQL中执行一些操作,观察日志文件是否有输出:
mysql> use sakila;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from store;
+----------+------------------+------------+---------------------+
| store_id | manager_staff_id | address_id | last_update |
+----------+------------------+------------+---------------------+
| 1 | 1 | 1 | 2006-02-15 04:57:12 |
| 2 | 2 | 2 | 2006-02-15 04:57:12 |
+----------+------------------+------------+---------------------+
2 rows in set (0.00 sec)
mysql> select * from staff;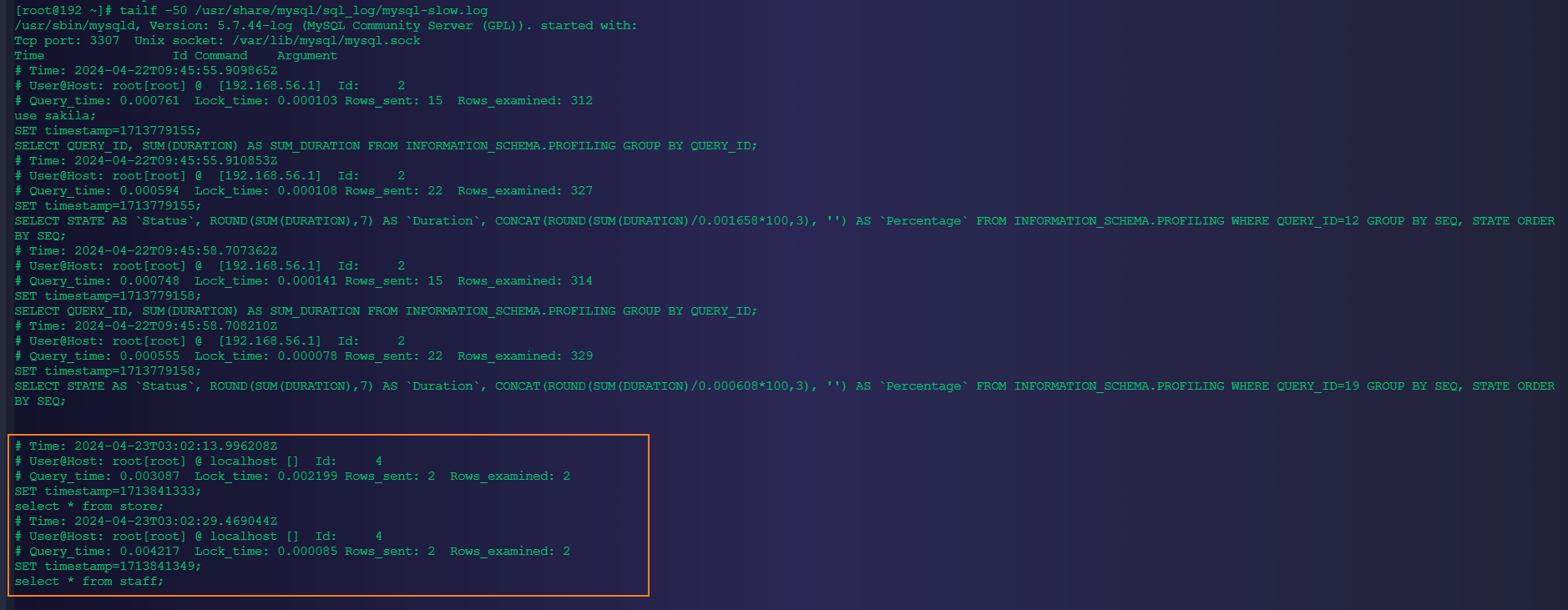
2.5.3、慢日志存储格式
# Time: 2024-04-23T03:02:29.469044Z
# User@Host: root[root] @ localhost [] Id: 4
# Query_time: 0.004217 Lock_time: 0.000085 Rows_sent: 2 Rows_examined: 2
SET timestamp=1713841349;
select * from staff;格式说明如下:
1、# Time: 2024-04-23T03:02:29.469044Z -------à查询的执行时间
2、# User@Host: root[root] @ localhost [] Id: 4 -------à执行sql的主机信息
3、# Query_time: 0.004217 Lock_time: 0.000085 Rows_sent: 2 Rows_examined: 2-------àSQL的执行信息:
- 1)、Query_time:SQL的查询时间
- 2)、Lock_time:锁定时间
- 3)、Rows_sent:所发送的行数
- 4)、Rows_examined:锁扫描的行数
- 3)、Rows_sent:所发送的行数
- 2)、Lock_time:锁定时间
4、SET timestamp=1713841349; -------àSQL执行时间
5、select * from staff; -------àSQL的执行内容
3、mysqldumpslow 使用
如何进行查看慢查询日志,如果开启了慢查询日志,就会生成很多的数据,然后我们就可以通过对日志的分析,生成分析报表,然后通过报表进行优化。接下来我们查看一下这个工具的用法:
注意:在mysql数据库所在的服务器上,而不是在mysql>命令行中

分析实例:
mysqldumpslow /usr/share/mysql/sql_log/mysql-slow.log
如上图所示就是分析的结果,每条结果都显示是执行时间,锁定时间,发送的行数,扫描的行数。这个工具是最常用的工具,通过安装mysql进行附带安装,但是该工具统计的结果比较少,对我们的优化锁表现的数据还是比较少。
4、pt-query-digest 分析使用
4.1、快速安装
2)mysql慢日志分析工具pt-query-digest安装_pt-digest官网下载-CSDN博客文章浏览阅读199次。安装环境,centos7先安装pt-query-digest依赖包,有6个,如下:perl-DBD-MySQL.x86_64perl-DBIperl-Time-HiRes.x86_64perl-IO-Socket-SSL.noarchperl-TermReadKey.x86_64perl-Digest-MD5命令yum install -y perl-DBD-MySQL.x86..._pt-digest官网下载https://blog.csdn.net/weixin_43456598/article/details/100540716
1、优先安装相关依赖包
yum install -y perl-DBD-MySQL.x86_64 perl-DBI perl-Time-HiRes.x86_64 perl-IO-Socket-SSL.noarch perl-TermReadKey.x86_64 perl-Digest-MD52、下载安装包
[root@192 src]# cd /usr/local/src
[root@192 src]# ls
[root@192 src]# wget https://www.percona.com/downloads/percona-toolkit/3.0.13/binary/redhat/7/x86_64/percona-toolkit-3.0.13-1.el7.x86_64.rpm
3、安装软件
[root@192 src]# ls
percona-toolkit-3.0.13-1.el7.x86_64.rpm
[root@192 src]# yum install -y percona-toolkit-3.0.13-1.el7.x86_64.rpm
4、查看版本号
[root@192 src]# pt-query-digest --version
pt-query-digest 3.0.13
[root@192 src]# 4.2、使用实例
4.2.1、查看服务器信息
pt-summary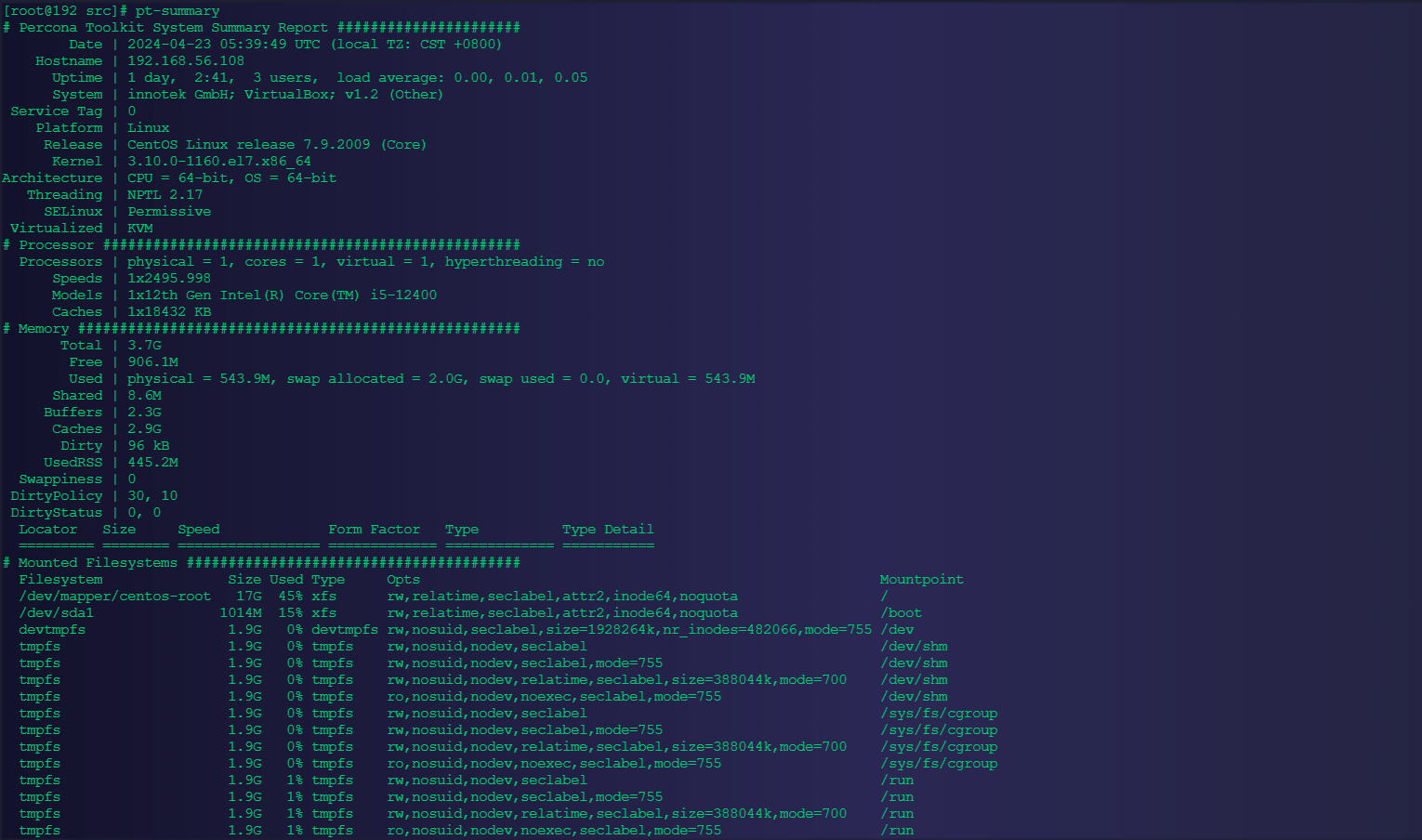
4.2.2、查看磁盘使用开销信息
pt-diskstats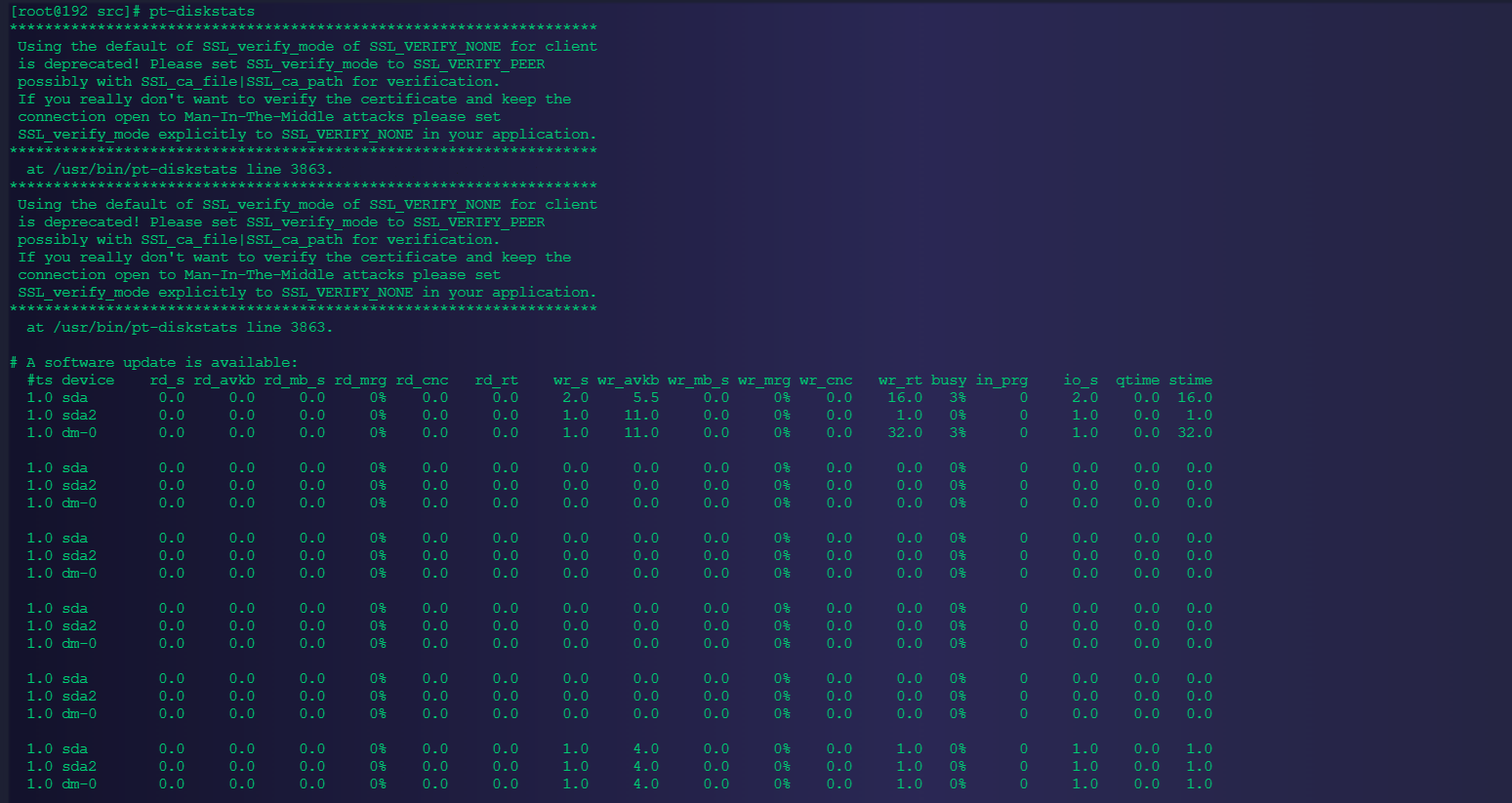
4.2.3、查看MySQL数据库信息
pt-mysql-summary --user=root --password=123456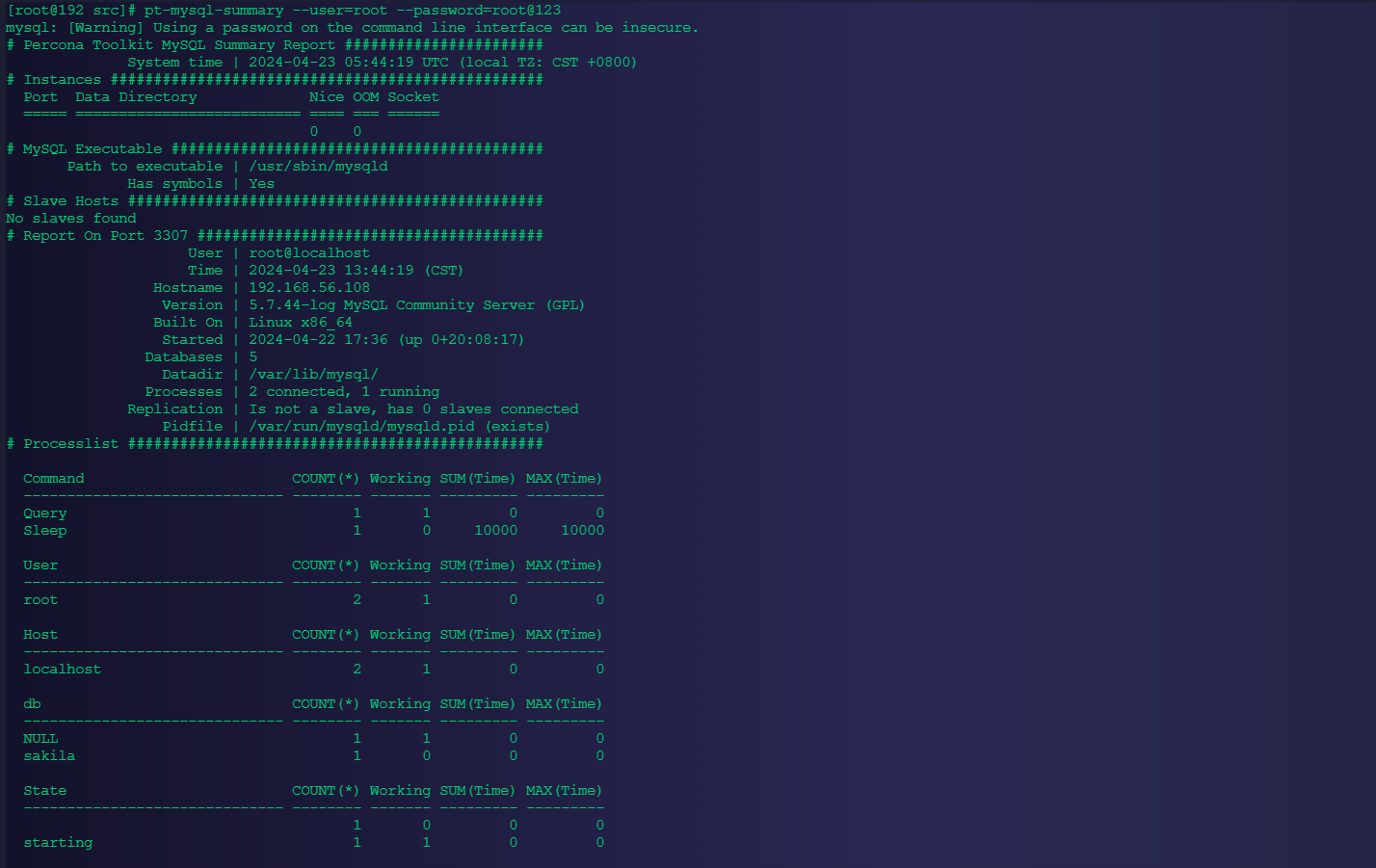
4.2.4、分析慢查询日志
[root@192 src]# pt-query-digest /usr/share/mysql/sql_log/mysql-slow.log
# 90ms user time, 80ms system time, 25.94M rss, 220.35M vsz
# Current date: Tue Apr 23 13:46:07 2024
# Hostname: 192.168.56.108
# Files: /usr/share/mysql/sql_log/mysql-slow.log
# Overall: 9 total, 7 unique, 0.00 QPS, 0.00x concurrency ________________
# Time range: 2024-04-22T09:45:55 to 2024-04-23T05:44:30
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 28ms 512us 16ms 3ms 16ms 5ms 725us
# Lock time 4ms 78us 2ms 405us 2ms 619us 138us
# Rows sent 80 0 22 8.89 21.45 8.68 1.96
# Rows examine 1.31k 2 329 149.22 313.99 148.76 44.60
# Query size 1011 19 212 112.33 202.40 72.12 97.36
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== ================================= ============= ===== ====== =====
# 1 0x09E8D04FD2462B493A23B0CB7839... 0.0159 56.6% 1 0.0159 0.00 SELECT INFORMATION_SCHEMA.TRIGGERS
# 2 0xF7C977062CE0183C5ADC8847FF93... 0.0042 15.0% 1 0.0042 0.00 SELECT staff
# 3 0x8448FB2A9B6C65404DC60F7FC7E5... 0.0031 11.0% 1 0.0031 0.00 SELECT store
# 4 0xCCAF11201C02BD2BF0A9CB7318D4... 0.0017 6.2% 1 0.0017 0.00 SELECT mysql.user
# 5 0x9277183CCDDC5C9148701A8733C0... 0.0015 5.4% 2 0.0008 0.00 SELECT INFORMATION_SCHEMA.PROFILING
# 6 0x733019F33E3027F6693EB59382A2... 0.0011 4.1% 2 0.0006 0.00 SELECT INFORMATION_SCHEMA.PROFILING
# MISC 0xMISC 0.0005 1.8% 1 0.0005 0.0 <1 ITEMS>
# Query 1: 0 QPS, 0x concurrency, ID 0x09E8D04FD2462B493A23B0CB7839AF05 at byte 2407
# Scores: V/M = 0.00
# Time range: all events occurred at 2024-04-23T05:44:19
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 11 1
# Exec time 56 16ms 16ms 16ms 16ms 16ms 0 16ms
# Lock time 7 282us 282us 282us 282us 282us 0 282us
# Rows sent 1 1 1 1 1 1 0 1
# Rows examine 0 8 8 8 8 8 0 8
# Query size 4 48 48 48 48 48 0 48
# String:
# Databases sakila
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms ################################################################
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `INFORMATION_SCHEMA` LIKE 'TRIGGERS'\G
# SHOW CREATE TABLE `INFORMATION_SCHEMA`.`TRIGGERS`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT COUNT(*) FROM INFORMATION_SCHEMA.TRIGGERS\G
# Query 2: 0 QPS, 0x concurrency, ID 0xF7C977062CE0183C5ADC8847FF9323B4 at byte 1804
# Scores: V/M = 0.00
# Time range: all events occurred at 2024-04-23T03:02:29
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 11 1
# Exec time 14 4ms 4ms 4ms 4ms 4ms 0 4ms
# Lock time 2 85us 85us 85us 85us 85us 0 85us
# Rows sent 2 2 2 2 2 2 0 2
# Rows examine 0 2 2 2 2 2 0 2
# Query size 1 19 19 19 19 19 0 19
# String:
# Databases sakila
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms ################################################################
# 10ms
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `sakila` LIKE 'staff'\G
# SHOW CREATE TABLE `sakila`.`staff`\G
# EXPLAIN /*!50100 PARTITIONS*/
select * from staff\G
# Query 3: 0 QPS, 0x concurrency, ID 0x8448FB2A9B6C65404DC60F7FC7E56F86 at byte 1596
# Scores: V/M = 0.00
# Time range: all events occurred at 2024-04-23T03:02:13
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 11 1
# Exec time 10 3ms 3ms 3ms 3ms 3ms 0 3ms
# Lock time 60 2ms 2ms 2ms 2ms 2ms 0 2ms
# Rows sent 2 2 2 2 2 2 0 2
# Rows examine 0 2 2 2 2 2 0 2
# Query size 1 19 19 19 19 19 0 19
# String:
# Databases sakila
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms ################################################################
# 10ms
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `sakila` LIKE 'store'\G
# SHOW CREATE TABLE `sakila`.`store`\G
# EXPLAIN /*!50100 PARTITIONS*/
select * from store\G
# Query 4: 0 QPS, 0x concurrency, ID 0xCCAF11201C02BD2BF0A9CB7318D42C19 at byte 2012
# Scores: V/M = 0.00
# Time range: all events occurred at 2024-04-23T05:44:19
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 11 1
# Exec time 6 2ms 2ms 2ms 2ms 2ms 0 2ms
# Lock time 11 409us 409us 409us 409us 409us 0 409us
# Rows sent 1 1 1 1 1 1 0 1
# Rows examine 0 4 4 4 4 4 0 4
# Query size 20 206 206 206 206 206 0 206
# String:
# Databases sakila
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms ################################################################
# 10ms
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `mysql` LIKE 'user'\G
# SHOW CREATE TABLE `mysql`.`user`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT COUNT(*), SUM(user=""), SUM(authentication_string=""), SUM(authentication_string NOT LIKE "*%") FROM mysql.user WHERE account_locked <> "Y" AND password_expired <> "Y" AND authentication_string <> ""\G
# Query 5: 0.67 QPS, 0.00x concurrency, ID 0x9277183CCDDC5C9148701A8733C04373 at byte 0
# Scores: V/M = 0.00
# Time range: 2024-04-22T09:45:55 to 2024-04-22T09:45:58
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 22 2
# Exec time 5 2ms 748us 761us 754us 761us 9us 754us
# Lock time 6 244us 103us 141us 122us 141us 26us 122us
# Rows sent 37 30 15 15 15 15 0 15
# Rows examine 46 626 312 314 313 314 1.41 313
# Query size 19 196 98 98 98 98 0 98
# String:
# Databases sakila
# Hosts 192.168.56.1
# Users root
# Query_time distribution
# 1us
# 10us
# 100us ################################################################
# 1ms
# 10ms
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `INFORMATION_SCHEMA` LIKE 'PROFILING'\G
# SHOW CREATE TABLE `INFORMATION_SCHEMA`.`PROFILING`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT QUERY_ID, SUM(DURATION) AS SUM_DURATION FROM INFORMATION_SCHEMA.PROFILING GROUP BY QUERY_ID\G
# Query 6: 0.67 QPS, 0.00x concurrency, ID 0x733019F33E3027F6693EB59382A27420 at byte 489
# Scores: V/M = 0.00
# Time range: 2024-04-22T09:45:55 to 2024-04-22T09:45:58
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 22 2
# Exec time 4 1ms 555us 594us 574us 594us 27us 574us
# Lock time 5 186us 78us 108us 93us 108us 21us 93us
# Rows sent 55 44 22 22 22 22 0 22
# Rows examine 48 656 327 329 328 329 1.41 328
# Query size 41 424 212 212 212 212 0 212
# String:
# Databases sakila
# Hosts 192.168.56.1
# Users root
# Query_time distribution
# 1us
# 10us
# 100us ################################################################
# 1ms
# 10ms
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `INFORMATION_SCHEMA` LIKE 'PROFILING'\G
# SHOW CREATE TABLE `INFORMATION_SCHEMA`.`PROFILING`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT STATE AS `Status`, ROUND(SUM(DURATION),7) AS `Duration`, CONCAT(ROUND(SUM(DURATION)/0.001658*100,3), '') AS `Percentage` FROM INFORMATION_SCHEMA.PROFILING WHERE QUERY_ID=12 GROUP BY SEQ, STATE ORDER BY SEQ\G
[root@192 src]# 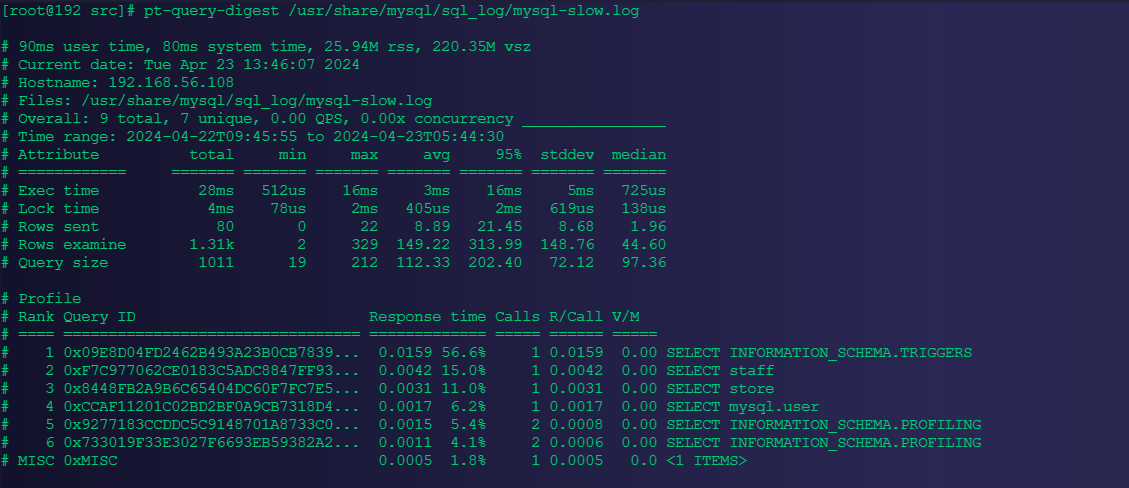
常见应用场景:
1、直接分析慢查询文件并输出结果
pt-query-digest slow.log > slow_report.log2、分析最近12小时内的查询
pt-query-digest --since=12h slow.log > slow_report2.log3、分析指定时间范围内的查询
pt-query-digest slow.log --since '2017-01-07 09:30:00' --until '2017-01-07 10:00:00'> > slow_report3.log4、分析指含有select语句的慢查询
pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i' slow.log> slow_report4.log5、针对某个用户的慢查询
pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' slow.log> slow_report5.log6、查询所有所有的全表扫描或full join的慢查询
pt-query-digest --filter '(($event->{Full_scan} || "") eq "yes") ||(($event->{Full_join} || "") eq "yes")' slow.log> slow_report6.log7、把查询保存到query_review表
pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_review--create-review-table slow.log8、把查询保存到query_history表
t-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_history--create-review-table slow.log_0001
pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_history--create-review-table slow.log_00024.2.5、查找MySQL的从库同步状态
pt-slave-find --host=localhost --user=root --password=123456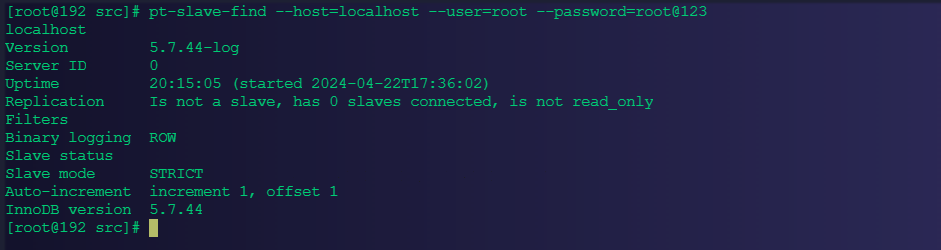
4.2.6、查看MySQL的死锁信息
pt-deadlock-logger --user=root --password=123456 localhost
4.2.7、从慢查询日志中分析索引使用情况
pt-index-usage /usr/share/mysql/sql_log/mysql-slow.log --host=localhost --user=root --password=root@123
4.2.8、查看数据库表中重复的索引
pt-duplicate-key-checker --host=localhost --user=root --password=123456
4.2.9、查看MySQL不同配置文件的差异
pt-config-diff /etc/my.cnf /etc/my_master.cnf
4.2.10、pt-find 查找MySQL表
#查找数据库里大于2G的表
[root@192 src]# pt-find --user=root --password=root@123 --tablesize +2G
#查找10天前创建,MyISAM引擎的表:
[root@192 src]# pt-find --user=root --password=root@123 --ctime +1 --engine InnoDB
#查看表和索引大小并排序
[root@192 src]# pt-find --user=root --password=root@123 --printf "%T\t%D.%N\n" | sort -rn
4.2.11、pt-kill 使用
1、杀掉查询时间超过50的查询会话
info后可变条件如"select|SELECT|delete|DELETE|update|UPDATE"
pt-kill --host=localhost --port=3306 --user=root --password=root --match-db='test' --match-info "select|SELECT" --busy-time 50 --victims all --interval 10 --daemonize --kill --log=/tmp/pt_select_kill.log #加--print可只打印符合的进程#2、杀掉来自某个IP的会话
pt-kill --host=localhost --port=3306 --user=root --password=root --match-db='test' --match-host "192.168.**.**" --busy-time 30 --victims all --interval 10 --daemonize --kill --log=/tmp/pt_select_kill.log3、杀掉来自某个用户的会话
pt-kill --host=localhost --port=3306 --user=root --password=root --match-db='test' --match-user "u2" --busy-time 30 --victims all --interval 10 --daemonize --kill --log=/tmp/pt_select_kill.log4、杀掉正在执行某个操作的会话
state后可变条件如Locked、login、copy to tmp table、Copying to tmp table、Copying to tmp table on disk、Creating tmp table、executing、Reading from net、Sending data、Sorting for order、Sorting result、Table lock、Updating
pt-kill --host=localhost --port=3306 --user=root --password=rootp --match-db='test' --match-command Query --match-state "Creating sort index" --run-time 1 --busy-time 30 --victims all --interval 10 --daemonize --kill --log=/tmp/pt_select_kill.log5、杀掉有query的进程
command后可变条件如Query、Sleep、Binlog Dump、Connect、Delayed insert、Execute、Fetch、Init DB、Kill、Prepare、Processlist、Quit、Reset stmt、Table Dump等
pt-kill --host=192.168.65.128 --port=3306 --user=root --password=rootpwd --match-db='db222' --match-command="Query" --busy-time 30 --victims all --interval 10 --daemonize --kill --log=/tmp/kill.log4.2.12、参考文章
Percona 数据库工具包 - 知乎Percona Toolkit简称pt工具,是Percona公司开发用于管理MySQL、MongoDB 的工具,功能包括检查主从复制的数据一致性、检查重复索引、定位IO占用高的表文件、在线DDL等,DBA熟悉掌握后将极大提高工作效率。 这些工具…![]() https://zhuanlan.zhihu.com/p/395574271Percona-toolkit工具详解 - 简书1. pt工具安装 2. 常用工具使用介绍 pt-archiver 归档表 pt-osc pt-table-checksum pt-table-sync mysql死锁监测 ...
https://zhuanlan.zhihu.com/p/395574271Percona-toolkit工具详解 - 简书1. pt工具安装 2. 常用工具使用介绍 pt-archiver 归档表 pt-osc pt-table-checksum pt-table-sync mysql死锁监测 ...![]() https://www.jianshu.com/p/36ace5c2bc8b
https://www.jianshu.com/p/36ace5c2bc8b
5、问题SQL定位思路
5.1、查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询;该工具可以很清楚的看出每个SQL执行的次数及百分比等信息,执行的次数多,占比比较大的SQL
5.2、IO大的sql
注意pt-query-digest分析中的Rows examine项。扫描的行数越多,IO越大。
5.3、未命中的索引的SQL
注意pt-query-digest分析中的Rows examine 和Rows Send的对比。说明该SQL的索引命中率不高,对于这种SQL,我们要重点进行关注。
6、explain 查询分析
6.1、执行计划查询
SQL的执行计划侧面反映出了SQL的执行效率,具体执行方式如下所示:在执行的SQL前面加上explain关键词即可;

6.2、执行计划字段说明
-
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
-
select_type列常见的有:
-
simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
-
primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个
-
union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
-
dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
-
union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
-
subquery:除了from子句中包含的子查询外,其他地方出现的子查询都可能是subquery
-
dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
-
derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
-
-
table,显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的<derived N>就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与<derived N>类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。
-
type,次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
-
system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
-
const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
-
eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
-
ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
-
fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
-
ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
-
unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
-
index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
-
range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
-
index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
-
index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
-
all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
-
-
possible_keys,查询可能使用到的索引都会在这里列出来
-
key,查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
-
key_len,用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
-
ref,如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
-
rows,这里是执行计划中估算的扫描行数,不是精确值
-
extra,这个列可以显示的信息非常多,有几十种,常用的有
-
distinct:在select部分使用了distinc关键字
-
no tables used:不带from字句的查询或者From dual查询
-
使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接。即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
-
using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
-
using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
-
using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询。
-
using sort_union,using_union,using intersect,using sort_intersection:
using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
-
using temporary:表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
-
using where:表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
-
firstmatch(tb_name):5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
-
loosescan(m..n):5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
-
-
filtered,使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数
7、慢查询优化案例
7.1、函数Max() 的优化
-- 用途:查询最后支付时间-优化max()函数
select max(payment_date) from payment;
-- 执行计划查看
explain select max(payment_date) from payment \G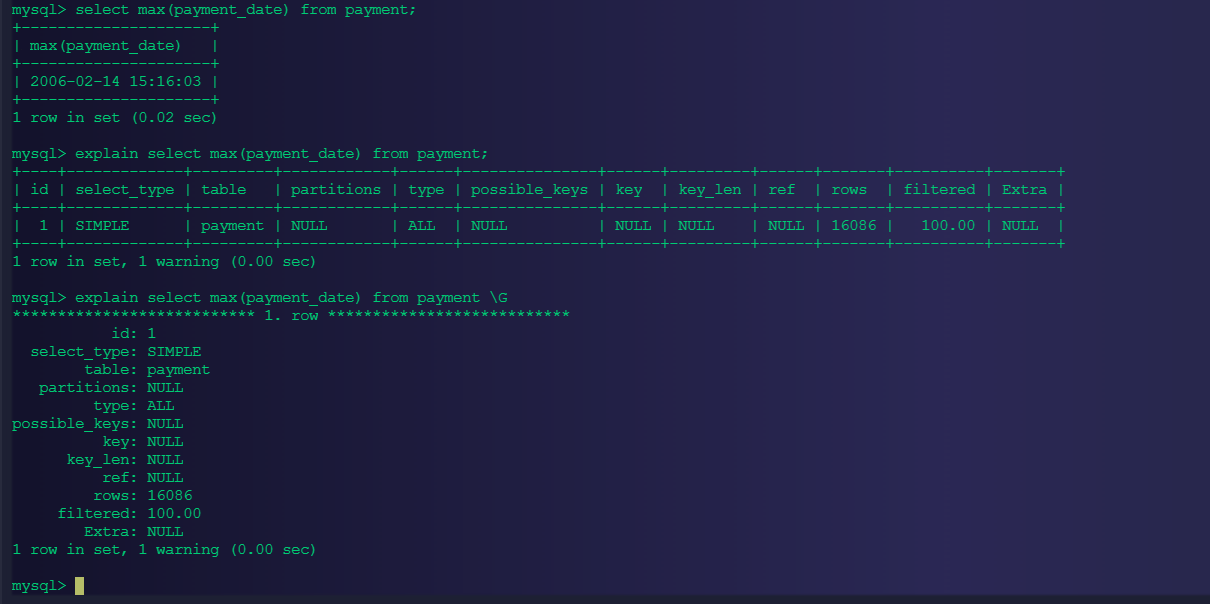
可以看到显示的执行计划,并不是很高效,可以拖慢服务器的效率,如何优化了?可以通过创建索引来进行优化。索引是顺序操作的,不需要扫描表,执行效率就会比较恒定
-- 创建索引
create index inx_paydate on payment(payment_date);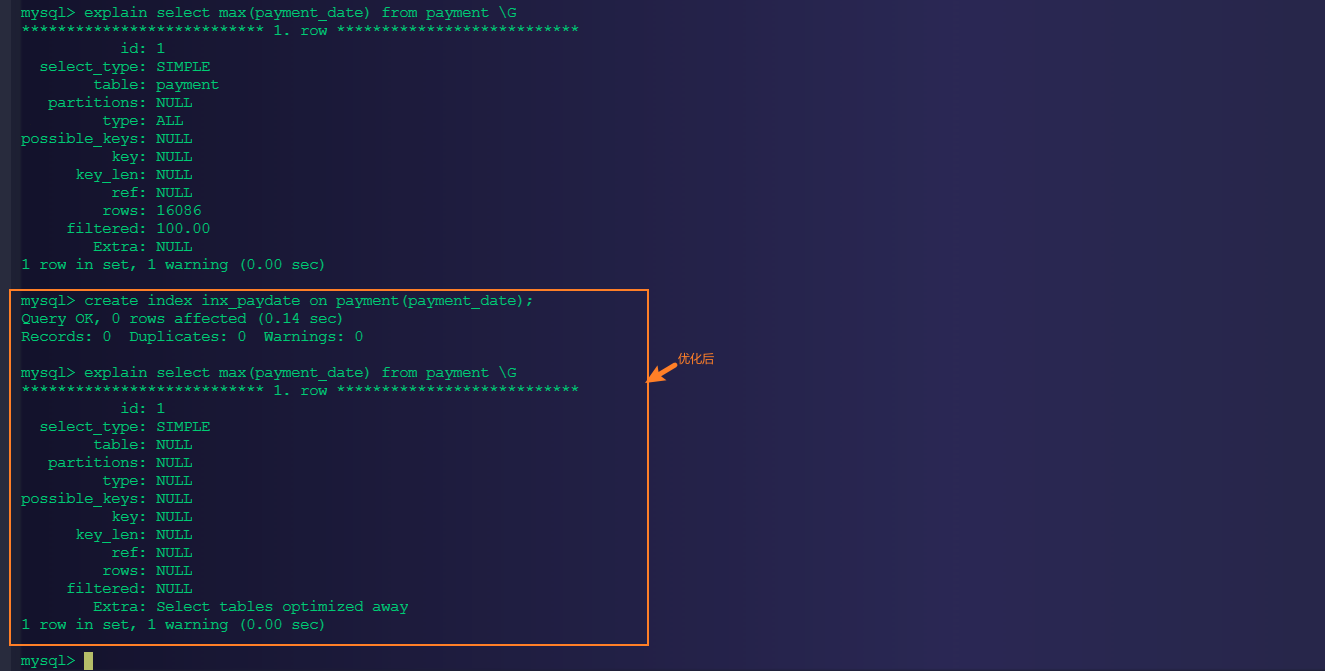
7.2、函数Count() 优化
需求:在一条SQL中同时查处2006年和2007年电影的数量
错误的执行方式:
-- 方式一:
select count(release_year='2006' or release_year='2007') from film;
-- 方式二:
select count(*) from film where release_year='2006' or release_year='2007';
2006和2007年分别是多少,判断不出来。正确的编写方式应该如下所示:
select count(release_year='2006' or null) as '06films',count(release_year='2007' or null) as '07films' from film;
7.3、group by 优化
需求:每个演员所参演影片的数量-(影片表和演员表)
explain select actor.first_name,actor.last_name,count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;
-- 优化后的
explain select actor.first_name,actor.last_name,c.cnt
from sakila.actor inner join (
select actor_id,count(*) as cnt from sakila.film_actor group by actor_id
)as c using(actor_id);
从上面的执行计划来看,这种优化后的方式没有使用临时文件和文件排序的方式了,取而代之的是使用了索引。查询效率老高了。
1、mysql 中using关键词的作用:也就是说要使用using,那么表a和表b必须要有相同的列。
2、在用Join进行多表联合查询时,我们通常使用On来建立两个表的关系。其实还有一个更方便的关键字,那就是Using。
3、如果两个表的关联字段名是一样的,就可以使用Using来建立关系,简洁明了。
7.4、Limit 查询优化
Limit常用于分页处理,时长会伴随order by从句使用,因此大多时候回使用Filesorts这样会造成大量的IO问题。
需求:查询影片id和描述信息,并根据主题进行排序,取出从序号50条开始的5条数据。
select film_id,description from sakila.film order by title limit 50,5;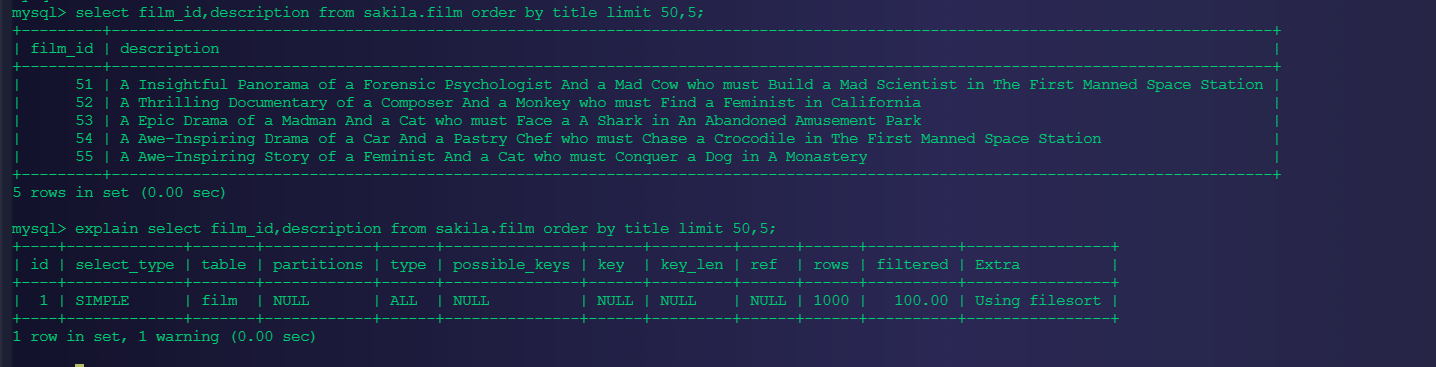
对于这种操作,我们该用什么样的优化方式了?
优化步骤1:
使用有索引的列或主键进行order by操作,因为大家知道,innodb是按照主键的逻辑顺序进行排序的。可以避免很多的IO操作。
select film_id,description from sakila.film order by film_id limit 50,5;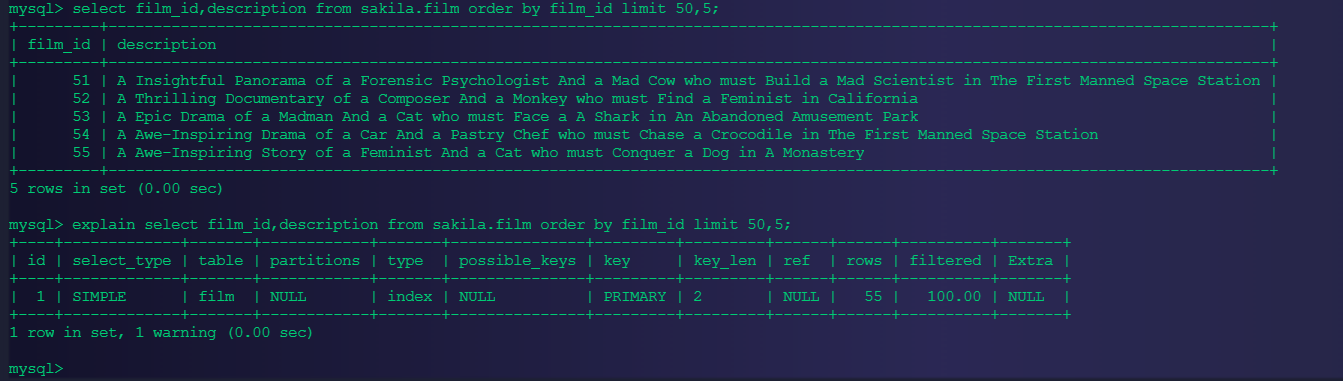
此时看似没啥问题,但是随着翻页越往后问题就出现了:
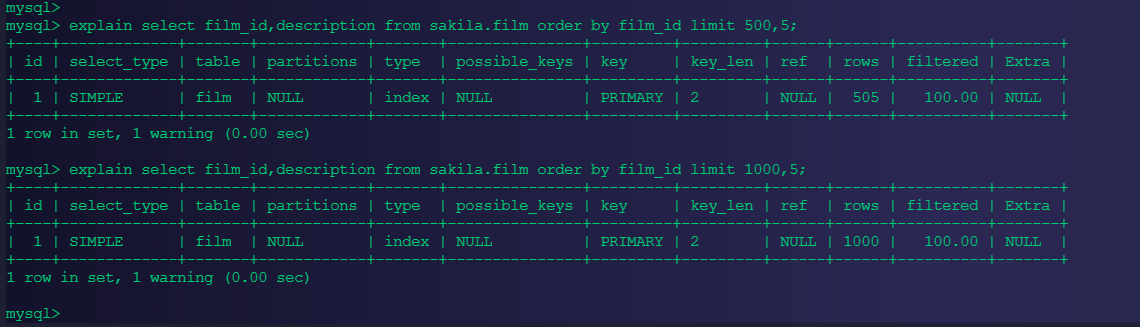
随着我们翻页越往后,IO操作会越来越大的,如果一个表有几千万行数据,翻页越后面,会越来越慢,因此我们要进一步的来优化。
优化步骤2:
记录上次返回的主键, 在下次查询时使用主键过滤。(说明:避免了数据量大时扫描过多的记录)上次limit是50,5的操作,因此我们在这次优化过程需要使用上次的索引记录值
select film_id,description from sakila.film where film_id >55 and film_id<=60 order by film_id limit 1,5;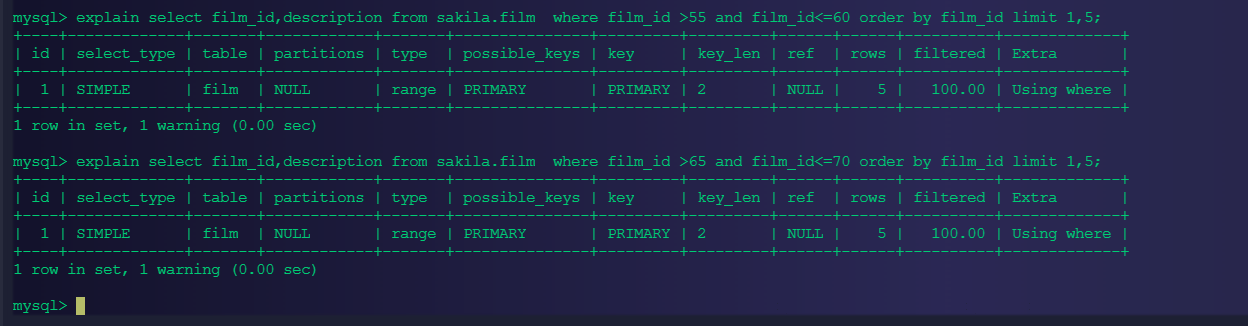
结论:扫描行数不变,执行计划是很固定,效率也是很固定的
注意事项:
主键要顺序排序并连续的,如果主键中间空缺了某一列,或者某几列,会出现列出数据不足5行的数据;如果不连续的情况,建立一个附加的列index_id列,保证这一列数据要自增的,并添加索引即可。
7.5、索引的优化
7.5.1、如何创建索引
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
1、ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
-
ALTER TABLE table_name ADD INDEX index_name (column_list)
-
ALTER TABLE table_name ADD UNIQUE (column_list)
-
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
-
-
说明:其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
2、CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引。
- CREATE INDEX index_name ON table_name (column_list)
- CREATE UNIQUE INDEX index_name ON table_name (column_list)
说明:table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
3、索引类型
- 在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为PRIMARY KEY或UNIQUE索引。对于单列惟一性索引,这保证单列不包含重复的值。对于多列惟一性索引,保证多个值的组合不重复。
PRIMARY KEY索引和UNIQUE索引非常类似。
事实上,PRIMARY KEY索引仅是一个具有名称PRIMARY的UNIQUE索引。这表示一个表只能包含一个PRIMARY KEY,因为一个表中不可能具有两个同名的索引。下面的SQL语句对students表在sid上添加PRIMARY KEY索引。
ALTER TABLE students ADD PRIMARY KEY (sid)4、删除索引
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
DROP INDEX index_name ON talbe_name
- ALTER TABLE table_name DROP INDEX index_name
- ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除掉table_name中的索引index_name。第3条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
如果从表中删除了某列,则索引会受到影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
5、查看索引
mysql> show index from tblname;
mysql> show keys from tblname;6、哪些情况使用了索引?
-
表的主关键字
-
自动建立唯一索引
-
表的字段唯一约束
-
直接条件查询的字段(在SQL中用于条件约束的字段)
-
查询中与其它表关联的字段
-
查询中排序的字段(排序的字段如果通过索引去访问那将大大提高排序速度)
-
查询中统计或分组统计的字段
-
表记录太少(如果一个表只有5条记录,采用索引去访问记录的话,那首先需访问索引表,再通过索引表访问数据表,一般索引表与数据表不在同一个数据块)
-
经常插入、删除、修改的表(对一些经常处理的业务表应在查询允许的情况下尽量减少索引)
-
数据重复且分布平均的表字段(假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。)
-
经常和主字段一块查询但主字段索引值比较多的表字段
-
对千万级MySQL数据库建立索引的事项及提高性能的手段
7.6、如何选择合适的列创建索引?
-
在where从句,group by从句,order by从句,on从句中的列添加索引
-
索引字段越小越好(因为数据库数据存储单位是以“页”为单位的,数据存储的越多,IO也会越大)
-
离散度大的列放到联合索引的前面
-- 示例
select * from payment where staff_id =2 and customer_id =584;这里创建索引时,是index(staff_id,customer_id)好,还是index(customer_id,staff_id)好。那我们怎么进行验证离散度好了?
A、我们先查看一下表结构
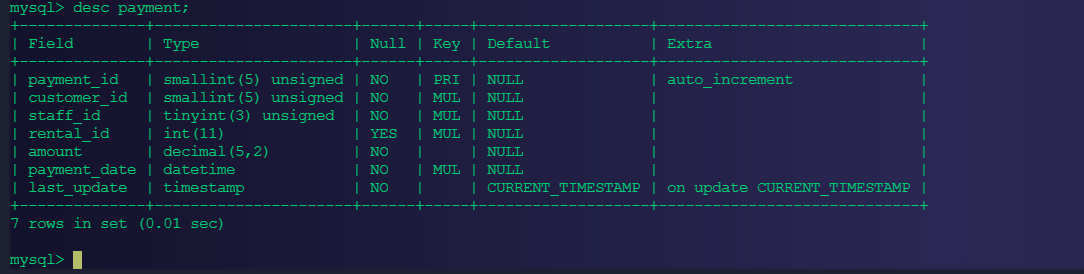
B、分别查看这两个字段中不同的id的数量,数量越多,则表明离散程度越大:因此可以通过下图看出:customer_id 离散程度大。

结论:由于customer_id 离散程度大,使用index(customer_id,staff_id)好
C、mysql联合索引
①命名规则 :表名_字段名
1、需要加索引的字段,要在where条件中
2、数据量少的字段不需要加索引
3、如果where条件中是OR关系,加索引不起作用
4、符合最左原则
②什么是联合索引
- 两个或更多个列上的索引被称作联合索引,又被称为是复合索引。
- 利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
7.7、索引优化
7.7.1、索引的维护及优化(重复及冗余索引)
增加索引会有利于查询效率,但会降低insert,update,delete的效率,但实际上往往不是这样的,过多的索引会不但会影响使用效率,同时会影响查询效率,这是由于数据库进行查询分析时,首先要选择使用哪一个索引进行查询,如果索引过多,分析过程就会越慢,这样同样的减少查询的效率,因此我们要知道如何增加,有时候要知道维护和删除不需要的索引。
7.7.2、什么是重复和冗余的索引
重复索引是指相同的列以相同的顺序建立的同类型的索引,如下表中的 primary key和ID列上的索引就是重复索引
create table test(
id int not null primary key,
name varchar(10) not null,
title varchar(50) not null,
unique(id)
)engine=innodb;
冗余索引是指多个索引的前缀列相同,或是在联合索引中包含了主键的索引,下面这个例子中key(name,id)就是一个冗余索引。
create table test(
id int not null primary key,
name varchar(10) not null,
title varchar(50) not null,
key(name,id)
)engine=innodb;
对于innodb来说,每一个索引后面,实际上都会包含主键,这时候我们建立的联合索引,又人为的把主键包含进去,那么这个时候就是一个冗余索引。
7.7.3、如何查找重复索引
使用pt-duplicate-key-checker工具检查重复及冗余索引:

7.7.4、索引维护的方法
由于业务变更,某些索引是后续不需要使用的,就要进行删除。在mysql中,目前只能通过慢查询日志配合pt-index-usage工具来进行索引使用情况的分析;

8、注意事项
8.1、索引创建
对于查询占主要的应用来说,索引显得尤为重要。很多时候性能问题很简单的就是因为我们忘了添加索引而造成的,或者说没有添加更为有效的索引导致。如果不加索引的话,那么查找任何哪怕只是一条特定的数据都会进行一次全表扫描,如果一张表的数据量很大而符合条件的结果又很少,那么不加索引会引起致命的性能下降。
但是也不是什么情况都非得建索引不可,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引。
8.2、复合索引
-- 比如有一条语句是这样的:
select * from users where area=’beijing’ and age=22;如果我们是在area和age上分别创建单个索引的话,由于mysql查询每次只能使用一个索引,所以虽然这样已经相对不做索引时全表扫描提高了很多效率,但是如果在area、age两列上创建复合索引的话将带来更高的效率。如果我们创建了(area, age,salary)的复合索引,那么其实相当于创建了(area,age,salary)、(area,age)、(area)三个索引,这被称为最佳左前缀特性。
因此我们在创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。
8.3、索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
8.4、使用短索引
对字符串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
8.5、排序的索引问题
mysql查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
8.6、like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
8.7、不使用NOT IN操作
NOT IN操作都不会使用索引将进行全表扫描。NOT IN可以NOT EXISTS代替